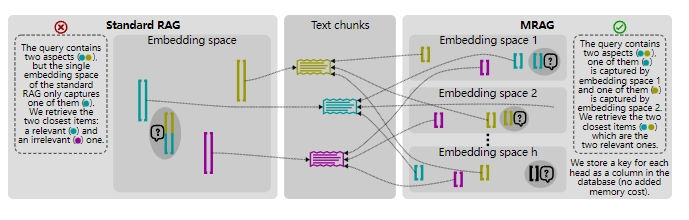
Multi-Head RAG By AiBard123 June 24, 2024 - 2 min read Multi-Head RAG 通过多头注意机制提升复杂查询文档检索准确性。 read more
Custom WebSearch Agent with LangGraph By AiBard123 June 24, 2024 - 2 min read Custom WebSearch Agent 使用 LangGraph 构建,可进行自定义网络搜索。 read more
Knowledge Graph RAG By AiBard123 June 24, 2024 - 2 min read Knowledge Graph RAG自动创建知识图谱和文档网络以提升RAG性能。 read more
AnimateDiff for ComfyUI By AiBard123 June 24, 2024 - 2 min read ### AnimateDiff for ComfyUI 简介 改进了ComfyUI的AnimateDiff整合,提供了进阶采样选项,可单独使用。 read more
Maestro By AiBard123 June 24, 2024 - 2 min read Maestro 是一个用来编排子代理的框架,支持Claude Opus、GPT和本地LLMs。 read more